Окт 11 2010 Linux 2.6.35
Долго и много гуглив, не один день пытаясь сообразить как решить проблемму постоянной активности диска в ОС Linux c ФС Ext4, я найдя в гугле ещё одну веб-подшивку почтовой рассылки про Linux в который как мне показалось были в основном ответы на этот вопрос, грамотных людей, специалистов, я найдя сейчас ответ самостоятельно - разочаровался как в этих "специалистах" так и в этом всемогущем гугле.
Я переживаю сейчас шок разочарования в англоязычном гугле - до этого было нормально что где-то там в просторах англоязычного комьпьютерного мира всегда где-то есть, далеко или близко, ответ на любой проблемный вопрос про компьютеры - теперь это не так. Впрочем, нужно было с самого начала до конца прочитать Documentation/laptops/laptop-mode.txt, там всё написано. Кстати у меня при моих настройках, установка в echo 5 > proc/sys/vm/laptop_mode делает диск активным, хммм... хотя должно быть наоборот.
На самом деле информацию я нашёл где она и была всё это время, в:
[KERNEL_TREE]/Documentation/filesystems/ext4.txt
[KERNEL_TREE]/Documentation/sysctl/vm.txt
[KERNEL_TREE]/Documentation/laptops/laptop-mode.txt
Теперь диск в моём ноутбуке не будет так много перегреваться до обычных 42-48 градусов цельсия. Теперь он будет перегреваться до 38 градусов. Т.е. проще говоря если у вас ноутбук и ФС на диске Ext4 и у вас всё не получается отправить диск в режим готовности аkа standby такими командами как:
hdparm -y /dev/sda или hdparm -S 3 /dev/sda
и после перехода в режим готовности диск почти сразу снова раскручивается хотя вы и разобрались уже с Advanced Power Managment диска командой:
hdparm -B 100 /dev/sda
то, вам конечно захотелось разобраться в чём тут дело и вы полезли в гугл за ответом а оказались здесь, то вы можете быть уверены что ваши проблеммы в прошлом. Надёюсь что и мои там. Да, и везде где фигурирует /dev/sda[5] имеется в виду мой диск, ваш может соответствовать другому файлу устройства и другому номера раздела.
Для начала ответы на ЧАВО которы я сам задавал гуглу:
В: Как узнать какой процесс работает с диском?
О: # echo 1 > /proc/sys/vm/block_dump
# cat /proc/kmsg
В: Как снизить количество обращений к диску?
О: # echo 10 > /proc/sys/vm/swappiness
# echo 100000 > /proc/sys/vm/dirty_expire_centisecs
# echo 100000 > /proc/sys/vm/dirty_writeback_centisecs
Как я понял это (100000) значит что секунда здесь равна 100 единицам а моё значение это 1000 секунд. А swappiness==10 вроде бы это значит что запись в раздел подкачки начнётся при 10% оставшейся свободной ОЗУ.
В: Как узнать текущий режим питания диска?
О: # while [ 0 ] ; do hdparm -C /dev/sda ; sleep 3 ; done
ИЛИ
#!/bin/ash
wt=3
at=0
st=0
it=0
printt=10
app="/sbin/hdparm"
disk="/dev/sda"
key="-C"
command="$app $key $disk"
while [ 0 ] ; do
$command | grep "standby" 1>/dev/null 2>/dev/null
if [ $? -eq 0 ] ; then
let "st=st+wt"
else
let "it=it+wt"
fi
sleep $wt
let "at=at+wt"
dirty=`cat /proc/meminfo | awk '/Dirty:/{print($2)}'`
if [ $at -gt $printt ] ; then
echo "All time: $at Stby time: $st Act time: $it Dirty: $dirty kB"
fi
done
В: Что такое грязная (dirty) память?
О: Грязная значит "возможно её необходимо записать на диск или в своп".
Нужно больше действий что бы высвободить эту память. Примерами могут
быть файлы которые ещё не были записаны. Они не записываются в память
слишком скоро в порядке уменьшения ввода/вывода (этот пассаж часть
перевода, там так и написано). Для примера, если вы пишите логи,
может быть лучше до того как вы закончите лог, до отправки его на
диск (тоже самое).
Выдержки из Documentation/sysctl/vm.txt
/proc/sys/vm/dirty_background_bytes (прим. значение: 0)
Содержит количество "грязной" памяти при котором фоновый демон обратной записи pdflush начнёт обратную запись.
Если dirty_background_bytes указан, то dirty_background_ratio становится функцией к этому значению т.е. (dirty_background_bytes / размер "загрязняемой" системной памяти).
/proc/sys/vm/dirty_background_ratio (прим. значение: 10)
Содержит, в виде процента от совокупной системной памяти, число страниц памяти, при котором демон обратной записи pdflush начнёт запись "грязных" данных.
/proc/sys/vm/dirty_bytes (прим. значение: 0; также, установка в 9000 запускает диск)
Содержит количество "грязной" памяти при котором процесс генерирующий дисковую запись самостоятельно начнёт обратную запись.
Если dirty_bytes установлено, dirty_ratio становится функцией к этому значению (dirty_bytes / размер "загрязняемой" системной памяти).
Прим: минимальное допустимое значения для dirty_bytes это две страницы (в байтах (октетах)); любое значение меньшее чем этот лимит, будет проигнорировано и будет востановлена прежняя конфигурация.
/proc/sys/vm/dirty_ratio (значение: 0; также, установка в 50, диск не запускает)
Содержит, в виде процента от общей системной памяти, число страниц при котором процесс который генерирует дисковую запись самостоятельно начнёт запись "грязных" данных.
/proc/sys/vm/dirty_expire_centisecs
Этот подстроечный параметр используется для определения того когда грязные данные уже достаточно старые чтобы подходить для записи демоном pdflush. Он выражается в 100'тых секунды. Данные которые были грязными в-памяти дольше чем этот интервал будут записаны в следующий раз когда демон pdflush проснётся.
/proc/sys/vm/dirty_writeback_centisecs
Демон обратной записи pdflush будет периодически просыпаться и записывать "старые" данны на диск. Этот подстроечный параметр выражает интервал между этими пробуждениями, в 100'тых секунды.
Установив его в ноль совсем отменяет периодичесие обратные записи.(прим. Что также приводит к активности диска и нагрузке в 100% на ЦПУ, вроде бы.)
Теперь что касается опций монтирования ФС Ext4.
commit=чиссек (по умолчанию равно 5 секундам)
ФС Ext4 можно указать синхронизировать все её данные и метаданные каждые 'чиссек' секунд. Число по умолчанию 5 секунд. Это значит что если у вас был сбой электроснабжения, вы утратите к максимум последние 5 секунд работы (ваша ФС не будет повреждена, благодаря журналированию). Это номинальное значение (или более меньшее значение) вредит производительности, но это хорошо для сохранности данных. Установка значения в 0 будет иметь тот же эффект, оставив его номинальное значение (5 секунд). Установка его в очень большое значение улучшит производительность.
inode_readahead_blks=число (кратное 2, напр. 16384)
Этот подстроечный праметр контролирует максимально число айнодов таблицы блоков, которое алгоритм предчтения таблицы айнодов ФС ext4, предсчитает в буфер кеша. Номинально значение равно 32 бкокам.
barrier=>0|1< или nobarrier
Это вкл./выкл. использование барьеров записи в коде jbd. barrier=0 выключает, barrier=1 включает. Также необходим стэк ввода/вывода способный работать с барьерами, и если jbd получит ошибку при записи барьера, это будет отменено с выдачей предупреждения. Барьеры записи принуждают к правильному упорядочиванию на диск журнальных (пакетных) записей, делая изменчивые дисковые кеши записи безопасными для использования, за счёт расплаты в виде производительности. Если ваши диски запитываются от батарей тем или иным образом, отключение барьеров может неопасно улучшить производительность. Опции монтирования "barrier" и "nobarrier" также могут быть использованы для включения или отключения барьеров, для согласованости с другими опциями монтирования ext4.
Суммируя, можно сказать что есть два типа ФС - не журналируемые и журналируемые. Журналирование используется для увеличения сохранности данных. ФС Ext3/4 это журналируемые файловые системы и это значит что при использовании на мобильных устройствах или на устройствах где необходимо обеспечить наименьшее энергопотребление дисками, необходимо производить монтирование разделов с таким настройками ФС при которых диск будет активным наименьшее количество времени. Например команда представленая ниже, перемонтирует уже смонтированый раздел /dev/sda5 c новыми опциями которые при использовании команды mount вида mount /dev/устройство (а не вида mount /dev/устройство /точка_монтировния) будут добавлены к опциям из файла /etc/fstab.
mount -o remount,rw,commit=600,inode_readahead_blks=16384,nobarrier /dev/sda5
Где commit`ы будут происходить каждые 10 минут (60 сек * 10 == 600), где в кеш ФС будет считываться 16384 блоков, и где отключено использование барьеров как и рекомендовано(?) в Documentation/filesystems/ext4.txt при питании от батарей.
Например мой нотбук с установленой ОС Ubuntu 10.04 при загруженом рабочем столе и одной консоли при холостой работе в течении 4995 секунд из них находился в режиме пониженого энергопотребления 4635 секунд (92.79%) а был активен в течении 360 секунд (7.20%). Такой результат был достигнут при опциях монтирования ФС Ext4 rw,errors=remount-ro,commit=600,inode_readahead_blks=16384,nobarrier, и при настройках /proc/sys/vm/* равных: swappiness == 60; dirty_expire_centisecs == 100000; dirty_writeback_centisecs == 1500 (опля ... должно было быть 100000); dirty_ratio == 50; dirty_background_bytes == 0; dirty_background_ratio == 10; dirty_bytes == 0;
среда, 13 октября 2010 г.
четверг, 10 июня 2010 г.
Файловая система Ext4 для Linux: часть 3
Эта заметка «Файловая система Ext4 для Linux: часть 3» продолжение первой части о жёстких дисках, и второй части о терминах ФС и файловой системе Ext4fs. Здесь я выбрал некоторые части из статьи Андрея Пешеходова (filesystems@nm.ru) — «Не новое, но хорошо доработанное старое: взгляд на ext4» о том что нового можно на сегодняшний день обнаружить в Ext4.
Что нового в ext4
16 терабайтный лимит размера раздела в ext3/2 обусловлен 32 битным номером блока и ограничен количеством групп блоков в файловой системе. Решение проблемы – введение 48 битных номеров блоков и ипользование метагрупп в ext4. При этом в ФС создаётся несколько метагрупп, каждая из которых является кластером такого количества групп блоков, дескрипторы которых могут храниться в одном блоке ФС. В 4 килобайтном блоке помещается 64 дескриптора нового формата, т. е. одна метагруппа может адресовать до 8 Gb дискового пространства. Резервные копии дескрипторов хранятся во второй и последней группе блоков каждой метагруппы. Все эти меры позволяют адресовать с помощью групп блоков 1 Eb дискового пространства и теперь поддерживаются разделы размером до 1 экзабайт при 4 килобайтном блоке.
В файловой системе ext3/2 размер файла ограничен 32-битным полем i_blocks в inode, содержащем количество физических блоков (512 байт), занимаемых файлом. В итоге, максимальный размер файла в ext3/2 ограничен величиной 2^32 * 512 = 2Tb, что для ФС нового поколения недостаточно. В ext4 эта проблема решена достаточно прямолинейно и бесхитростно: разрядность поля i_blocks увеличена до 48 бит, размер теперь исчисляется в логических блоках. В итоге размер файла ext4 ограничен только 32-битным номером логического блока в текущем формате экстента и составляет 16 Tb.
Объем каталога ext3/2 ограничен величиной в 32 000 файлов. В ext4 этот лимит полностью устранен – то есть количество файлов в одном каталоге там не ограничено. Для поддержки больших каталогов в ext4, вместо односвязного списка, используется схема индексирования их элементов с помощью так называемых HTree-структур – своего рода B-деревьев постоянной глубины, индексирующих элементы директории по 32-битному хэшу имени. Для каталогов, содержащих более 10 000 файлов, производительность поиска имени возросла в 50-100 раз относительно ext3/2 .
Файловая система ext3/2 отслеживает блоки данных файлов и каталогов с помощью косвенно-блочной схемы. Этот подход достаточно эффективен для сильно фрагментированных или маленьких файлов, но очень накладен для больших хорошо упакованных файлов – особенно на операциях удаления/усечения.
Для решения этого реализованы экстенты. Экстентом называется дескриптор, определяющий участок в несколько непрерывно расположенных дисковых блоков. В ext4 экстент может адресовать до 128 MiB дискового пространства при 4 KiB блоке. 4 экстента могут храниться прямо в inode – их вполне достаточно для небольших или нефрагментированных файлов. Когда встроенных экстентов не хватает, для адресации блоков файла используется дерево экстентов постоянной глубины. Корень этого дерева хранится в inode, сами экстенты – в листьях.
Ext3 поддерживает inodes различного размера, задаваемого во время mke2fs параметром -I [inodes_size]. В ext4 минимальный размер inode увеличен вдвое – до 256 байт. Для сохранения совместимости с кодом драйвера ext3 и e2fsck размеченная часть inode имеет старый формат. В дополнительной секции расположены несколько новых полей (к примеру, наносекундные временные штампы) и динамическая область, используемая под расширенные атрибуты (extended attributes, EAs). Размер дополнительной секции может меняться от версии к версии и хранится в поле i_extra_isize, следующем сразу за старой 128 битной частью. Суперблок содержит 2 связанных с этим вопросом поля: s_min_extra_size (гарантированный размер дополнительной статической области) и s_want_extra_size (желаемый некоей версией, но не гарантируемый размер экстра-области). Оставшееся пространство в inode может быть использовано для хранения встроенных расширенных атрибутов прямо в inode, что существенно увеличивает производительность их обработки. Также попрежнему доступен дополнительный EA блок, позволяющий хранить еще 4 Kb атрибутданных для каждого файла. Возможность хранения большего количества EAs в форме регулярного каталога не реализована.
В ext4 предразмещение реализовано вполне традиционно – неинициализированный экстент имеет специальную пометку, обнаружив которую при попытке чтения экстента, файловая система вернет приложению блок нулей. При записи в середину такого экстента он разбивается на две части – одна дополняется нулями и пишется на диск, другая остается "виртуальной". В настоящее время все файловые системы Linux, располагающие соответствующим функционалом, принимают запросы на предразмещение через ioctl(). В будущем (по скольку таких ФС становится все больше) планируется введение специального системного вызова, реализующего posix_fallocate API.
Отложенное размещение – хорошо известная техника, суть которой заключается в отсрочке выделения аллокатором ФС блоков до времени сброса страниц (flush). Это позволяет обеспечить более эффективную, сточки зрения фрагментации и нагрузки на CPU, группировку запросов на размещение. Короткоживущие временные файлы при этом могут вообще не получить дискового воплощение, оставаясь лишь в кэше. С появлением отложенного размещения стало возможно реализовать т.н. многоблочное размещение, при котором дисковое пространство выделяется сразу целыми экстентами, что исключает множество лишних вызовов ext4_get_blocks() и ext4_new_blocks() и уменьшает нагрузку на процессор. Многоблочное размещение в ext4 реализовано через сбор информации о свободных экстентах в каждой группе блоков при монтировании ФС и организации ее хэширования в оперативной памяти. Цена этого решения – увеличение времени монтирования ФС.
Файловая система Ext4 для Linux: часть 4
Эта заметка «Файловая система Ext4 для Linux: часть 4» продолжение первой части о жёстких дисках, и второй части о терминах ФС и файловой системе Ext4fs, и 3-й части о новинках. В этой части дело дошло и до разбора полётов — я (таки) перевёл :-) руководство на mke2fs версии 1.41.11 (14-Mar-2010) т. е. утилиту создания файловых систем семейства Ext, и это было весело хотя кое где и не очень. Вообще же в этом пакете программ откуда родам эта утилита довольного много других интересных вещей, т. е. разных утилит для работы с ФС, всего там есть вот что: e2fsck , debugfs , mke2fs , badblocks , tune2fs , dumpe2fs , logsave , e2image , e2undo , e2label , resize2fs , chattr , lsattr , mklost+found, filefrag, e2freefrag … мда, есть над чем поработать... сисадминам.
Страница руководства утилиты mke2fs
mke2fs - создание файловых систем ext2/ext3/ext4
mke2fs [ -c | -l имя-файла ] [ -b размер-блока ] [ -f размер-фрагмента ] [ -g блоков-на-группу ] [ -G число-групп ] [ -i байтов-на-айнод ] [ -I размер-айнода ] [ -j ] [ -J опции-журнала ] [ -K ] [ -N число-айнодов ] [ -n ] [ -m процент-зарезервированых-блоков ] [ -o ОС-создатель ] [ -O опция[,...] ] [ -q ] [ -r ревизия-ФС ] [ -E расширеные-опции ] [ -v ] [ -F ] [ -L этикетка-тома ] [ -M преды.-точка-монтирования ] [ -S ] [ -t тип-ФС ] [ -T тип-использования ] [ -U UUID ] [ -V ] устройство [ число-блоков ]
mke2fs -O журнальное-устройство [ -b размер-блока ] [ -L метка-тома ] [ -n ] [ -q ] [ -v ] внешний-журнал [ число-блоков ]
ОПИСАНИЕ
mke2fs используется для создания файловых систем типа ext2, ext3, или ext4; обычно ФС пишется на раздел диска. Устройство это специальный файл связанный с устройством хранения (т. е. /dev/hdXX). Число-блоков это число блоков на устройстве. Если не указано, mke2fs автомагически уясняет размер ФС. Если вызывается как mkfs.ext3 то создаётся журнал как если бы была указана опция -j.
Параметры работы для создания наново файловой системы, если они не переопределены опциями ниже, контролируются конфигурационным файлом /etc/mke2fs.conf. Для лучшего знакомства ознакомьтесь со страницей справки mke2fs.conf(5).
ОПЦИИ
-b размер-блока Указать размер блоков в байтах. Приемлемые значения размера блоков 1024, 2048 и 4096 байтов на блок. Если значение не указано, размер эвристически определяется исходя из размера файловой системы и предполагаемого использования ФС (см. опцию -T ). Если значение отрицательное число, тогда mke2fs перейдёт к эвристике для определения подходящего размера блока, с ограничением что размер блока будет как минимум с размер-блока байтов. Эта опция полезна при использовании с определёнными устройствами хранения которые требуют что бы размер блока был множимым от 2k.
-c Проверить устройство на наличие сбойных блоков перед созданием ФС. Если эта опция указывается дважды то применяется медленный тест чтение-запись вместо быстрого теста только-чтение.
-E расширенные-опции Установить расширенные опции для ФС. Расширенные опции разделяются запятыми, и могут принимать аргумент используя знак равенства (“=“). Опция -E раньше определялась с помощью -R в ранних версиях утилиты mke2fs. Опция -R по прежнему обрабатывается для обратной совместимости. Поддерживаются нижеследующие расширенные опции:
stride=размер-шага Сконфигурировать ФС для RAID массива с параметром размер-шага к количеству блоков ФС. Это значение есть число читаемых или записываемых на устройство блоков, до осуществления перехода к следующему устройству, что иногда обозначается как размер куска. Это в основном влияет на расположение метаданных ФС, например битовых карт при работе утилиты mke2fs во избежание размещения их на одном устройстве, что может повредить производительности. Это значение также может быть использовано алокатором блоков.
stripe-width=размер-стежка Сконфигурировать ФС для RAID массива с параметром размер-стежка к количеству блоков ФС на стежок. Обычно это размер-шага * N, где N это количество устройств для хранения данных в RAID (т. е. для RAID-5, там есть одно устройство для хранения данных для коррекции ошибок, и поэтому N будет числом устройств в массиве, минус 1). Это позволяет алокатору блоков предотвращать чтение-модификацию-запись данных чётности в RAID стежке, когда это возможно, в период записи данных.
resize=макс-рабочее-увеличение Зарезервировать место так что бы таблица дескрипторов групп блоков могла разрастаться, для поддержки ФС, с количеством блоков для этого равным макс-рабочее-увеличение.
lazy_itable_init[=<0>] Если включено и опция uninit_bg также активирована, таблица айнодов не будет полностью инициализирована утилитой mke2fs. Это заметно ускоряет инициализацию ФС, но также требует что бы ядро завершило инициализацию ФС в фоновом режиме при первом монтировании ФС. Если аргумент опции опущен, то он устанавливается в 1 для включения ленивой инициализации таблицы айнодов.
test_fs Установить пометку в суперблоке ФС, указывающую что она может монтироваться используя экспериментальный код, например код ФС ext4dev.
-f размер-фрагмента Указать размер фрагментов в байтах. (Прим. Фрагмент это файл или часть файла меньшая чем размер блока ФС, эта функция ФС используется для эффективного использования т. е. заполнения физических блоков, вроде бы. На данный момент эта возможность не реализована.)
-F Принудить mke2fs создать файловую систему, даже если указанное устройство не является разделом на специальном блочном устройстве, или если другие параметры не имеют смысла. В порядке принуждения mke2fs к созданию ФС даже если файловая система находится в работе или смонтирована (по настоящему опасное намерение), эта опция должна быть указана дважды.
-g блоков-на-группу Указать число блоков в группе блоков. Обычно у пользователя не может быть причин для установки этого параметра, так как номинальные установки оптимальны для ФС. (Для администраторов которые создают ФС на RAID массивах, предпочтительнее использовать параметр RAID stride как часть опции -E нежели чем манипулировать количеством блоков на группу.) Эта опция обычно используется разработчиками в целях тестирования.
-G число-групп Указать число групп блоков которые будут упакованы вместе для создания большой виртуальной группы (или «flex_bg группы») в ФС ext4. Это улучшает локализацию метаданных и производительность при нагруженной обработке метаданных. Число групп должно быть степенью 2-х и может быть указано только если опция flex_bg включена в ФС.
-i байтов-на-айнод Указать отношение байтов/айнодов. Mke2fs создаёт айнод для каждых байтов-на-айнод байтов из пространства устройства. Чем больше отношение байтов-на-айнод, тем меньше айнодов будет создано. Это значение в общем не должно быть меньше чем размер блока в файловой системе, так как в этом случае будет создано больше айнодов чем вообще может быть использовано. Не забудьте что не возможно увеличить число айнодов в ФС после её создания, так что будьте внимательны выбирая правильное значение для этого параметра.
-I размер-айнода Указать размер айнодов в байтах. Mke2fs сама по себе создаёт 256-байтные айноды. Также в выпусках ядра после версии 2.6.10 и в некоторых ранних ядрах от независимых поставщиков возможно использовать айноды размером больше чем в 128 байтов для хранения расширенных атрибутов для улучшения производительности. Значение размера айнода должно быть его произведением на 2-ва, большим или равным 128. Чем больше размер айнода тем больше займёт места таблица айнодов, и это сократит используемое пространство в ФС и также может негативно повлиять на производительность. Расширенные атрибуты хранимые в больших айнодах не доступны старым версиям ядра, и такие ФС не могут быть смонтированы совсем с ядром версии 2.4. Изменить это значение после создания ФС не возможно.
-j Создать ФС с журналом ext3. Если опция -J не указана, будут использованы номинальные параметры журналирования для создания журнала подходящего размера (исходя из рамеров ФС) хранимого в ФС. Заметьте что вы должны использовать ядро с поддержкой ext3 для того что бы фактически использовать журнал.
-J опции-журнала Создать журнал ext3 используя опции указанные в командной строке. Опции журнала разделяются запятыми, и могут принимать аргумент используя знак равенства (“=“). Поддерживаются следующие опции журнала:
size=размер-журнала Создать внутренний журнал (т. е., хранимый внутри ФС) с размером размер-журнала мегабайтов. Размер журнала должен быть как минимум 1024 блоков файловой системы (т. е., 1 МиБ используя 1 КиБ блоков, 4 МиБ при использовании 4 КиБ блоков, и тп.) и не может быть больше чем 102,400 блоков ФС.
device=внешний-журнал Присоединить ФС к журнальному блочному устройству расположенному на внешний-журнал. Внешний журнал должен быть уже создан используя команду:
mke2fs -O журналируемое-устройство внешний-журнал Заметьте что внешний-журнал должен был быть создан с тем же размером блока как и в новой ФС. В дополнение, хотя и существует возможность присоединения множества ФС к одному внешнему журналу, ядро Linux и e2fsck(8) на данный момент пока не поддерживают разделяемые внешние журналы.
Вместо прямого указания имени устройства, внешний-журнал также может быть указан как LABEL=метка или UUID=UUID для обнаружение внешнего журнала или по метке тома или по UUID хранимому в суперблоке ext2 в начале журнала. Используйте dumpe2fs(8) для отображения метки тома или UUID устройства с журналом. См. также опцию -L утилиты tune2fs(8).
Только одна из опций size или device может быть указана для файловой системы.
-K Хранить, не пытаться отбрасывать блоки при работе mkfs (отбрасывание блоков изначально полезно на устройствах SSD и редких устройствах с реализованным тонким резервированием). (Прим. Здесь что то непонятное, так как block discard это часть техники «тонкого резервирования» места на устройстве хранения и это всё должно работать в работающей ФС а не на момент создания ФС, вроде бы.)
-l имя-файла Читать листинг сбойных блоков из файла. Заметьте что номера блоков в этом листинге должны быть сгенерированы используя тот же размер блока какой используется в mke2fs. В результате опция -c утилиты mke2fs это гораздо более простой и безошибочный метод проверки устройства на сбойные блоки перед его форматированием, так как mke2fs передаст автоматически корректные параметры утилите badblocks.
-L новая-метка-тома Установить метку тома для ФС из значения новая-метка-тома. Максимальная длина метки тома 16 байт.
-m процент-зарезервированых-блоков Указать процент блоков ФС зарезервированных для суперпользователя. Этот процент избегает фрагментации, и позволяет демонам с правами root, таким как syslogd(8), продолжать функционировать корректно после того как непривилегированные процессы уже были лишены возможности записи в файловую систему. Номинально это значение равно 5%.
-M преды.-точка-монтирования Установить последнюю директорию монтирования ФС. Это может быть полезно для утилит которые по последней директории монтирования решают куда ФС должна быть смонтирована.
-n Заставляет mke2fs не создавать фактически ФС, но отображать то что она сделает при создании ФС. Это может быть использовано для определения расположения резервных копий суперблока для определённой файловой системы, до тех пор пока параметры mke2fs которые были переданы совпадают с параметрами переданными когда ФС изначально была создана. (С добавленной опцией -n, конечно!)
-N число-айнодов Переопределить номинальное вычисление числа айнодов которые должны быть выделены на создание ФС (которое основано на числе блоков и значении отношения байтов-на-айнод). Это позволяет пользователю указывать желаемое число айнодов напрямую.
-o ОС-создатель Переопределить номинально значение поля «операционная система создатель» в ФС. Поле «создатель» номинально устанавливается к имени ОС для которой исполняемый файл утилиты mke2fs был скомпилирован.
-O опция[,...] Создать ФС с заданными возможностями (опциями файловой системы), тем самым переопределяя номинальные опции ФС. Возможности включённые номинально определяются отношениями опций в base_features, или в секции [defaults] в конфигурационном файле /etc/mke2fs.conf, или в субсекции [fs_types] для определения типа использования ФС согласно опции -T, далее адаптируются с помощью отношений опций из субсекции [fs_types] для файловой системы и типов использования. Смотрите страницу руководства mke2fs.conf(5) для получения подробностей.
Настройки конфигурации специфичные для типа ФС расположенные в секции [fs_types] переопределят глобальные номинальные настройки в секции [defaults].
Набор опциональных возможностей ФС далее будет изменён используя или набор возможностей определённый этой опцией, или если эта опция не дана, с помощью отношений из default_features, относительно типа создаваемой ФС, или с помощью секции [defaults] в конфигурационном файле.
Набор возможностей ФС состоит из списка опциональных возможностей, разделённых запятой, которые будут активированы. Для отмены возможности, просто предварите имя опции символом (“^“) каретки. Псевдо-опция ФС «none» очистит все опциональные возможности ФС.
dir_index Использовать хешированые б-деревья для ускорения обзора больших директорий.
extent Вместо использования непрямой схемы блоков для хранения расположения блоков данных, в айноде, использовать экстенты. Это гораздо более эффективная кодировка которая ускоряет доступ к ФС, особенно к большим файлам.
filetype Хранить информацию о типе фалов в записях директорий.
flex_bg Позволить располагать метаданные групп блоков (битовые карты и таблицы айнодов) где угодно на устройстве хранения. В дополнение, mke2fs разместит метаданные каждой группы блоков вместе начиная от первой группы блоков каждой «flex_bg группы». Размер группы flex_bg может быть указан с помощью опции -G.
has_journal Создавать журнал ext3 (как вместе с опцией -j).
journal_dev Создать внешний журнал ext3 на заданном устройстве вместо обычной ext2 ФС. Заметьте что внешний журнал должен быть создан используя тот же размер блока как и ФС которая будет его использовать.
large_file ФС может нести файлы которые больше 2 ГиБ. (Современные ядра устанавливают эту опцию автоматически когда создаётся файл > 2 ГиБ.)
resize_inode Резервировать место что бы таблица дескрипторов групп блоков могла расти в будущем. Полезно при изменении размера работающей ФС с помощью программы resize2fs. Номинально mke2fs попытается зарезервировать достаточно места так что бы ФС могла вырасти в 1024 раз от начального размера. Это может быть изменено при помощи расширенной опции resize.
sparse_super Создать ФС с меньшим количеством резервных копий суперблока (это сохраняет место на больших ФС).
uninit_bg Создать ФС без инициализации всех групп блоков. Эта опция также включает контрольные суммы и статистику наиболее-используемый-айнод в каждой группе блоков. Эта опция может заметно ускорить процесс создания ФС (если включено lazy_itable_init), и также может драматически уменьшить время работы e2fsck. Эта возможность поддерживается только в ФС ext4 в недавних ядрах Linux.
-q Тихое выполнение. Полезно если mke2fs используется в скрипте.
-r ревизия-ФС Установить ревизию ФС для новой файловой системы. Заметьте что ядра версий серии 1.2 поддерживают только ревизию 0 файловой системы. Номинально создаётся ревизия 1 файловой системы.
-S Записать только суперблок и дескрипторы групп. Это полезно если все суперблоки и резервные суперблоки повреждены, и требуется метод последнего шанса. Это заставляет mke2fs пере-инициализировать суперблок и дескрипторы блоков, не затрагивая при этом таблицу айнодов и битовые карты блоков и айнодов. Утилита e2fsck должна быть использована немедленно после применения этой опции, и при этом нет гарантии что каике либо данные будут восстановимы. Критично то что нужно указать корректный размер блока файловой системы при использовании этой опции, или же шанса на восстановление не будет.
-t тип-ФС Указать тип файловой системы (т. е., ext2, ext3, ext4, и тп.) которая будет создана. Если эта опция не указана, mke2fs выберет это значение или исходя из имени своего вызова (для примера, используя имя вида mkfs.ext2, mkfs.ext3 и тп.) или из настроек определённых в файле /etc/mke2fs.conf(5). Эта опция контролирует какие опции ФС используются номинально, основываясь на разделе fstypes в файле /etc/mke2fs.conf(5).
Если опция -O используется явным образом для добавления или удаления опций файловой системы которые должны быть использованы в наново создаваемой файловой системе, результирующий набор опций может оказаться не поддерживаемым указанным типом ФС. (т. е., команда «mke2fs -t ext3 -O extents /dev/sdXX» создаст файловую систему которая не поддерживается реализацией ext3 как оно исполнено в ядре; и команда «mke2fs -t ext3 -O ^has_journal /dev/hdXX» создаст файловую систему не имеющую журнала и поэтому не она будет поддерживаться кодом модуля файловой системы ext3 в ядре Linux.)
-T тип-использования[,...] Указать как файловая система будет использоваться, чтобы утилита mke2fs могла выбрать оптимальные параметры ФС для этого типа использования. Поддерживаемые типы использования определены в конфигурационном файле /etc/mke2fs.conf(5). Пользователь может указать один или больше типов использования используя разделённый запятыми список. Если эта опция не задействована, mke2fs подберёт один номинальный тип использования основываясь на размере создаваемой файловой системы. Если размер файловой системы меньше или равен 3 МиБ, mke2fs использует тип использования floppy (дискета). Если размер файловой системы больше 3-х но меньше или равен 512 МиБ, mke2fs(8) использует тип использования small (малое). Иначе, mke2fs(8) использует номинальный тип использования default (номинал).
-U UUID Создать ФС с указанным UUID.
-v Информативный вывод.
-V Вывести версию mke2fs и завершится.
воскресенье, 6 июня 2010 г.
Файловая система Ext4 для Linux: часть 2
Эта заметка «Файловая система Ext4 для Linux: часть 2» продолжение первой части о жёстких дисках и файловой системе Ext4fs. Здесь я попытался собрать в одном месте информацию о терминах этой ФС и о том что они означают. В общем и целом, это довольно туманный вопрос, по прежнему есть много непонятного, а информация которая была рассмотрена по этому вопросу не полна и не даёт чёткого представления об внутреннем устройстве ФС. В общем, надеюсь что я ничего не упустил, и ещё больше что ничего не перепутал.
Базовые понятия
Раздел (Partition) - структура данных ОС, содержащая указатели, на множество физических блоков устройства хранения данных, обязательно являющихся смежными. Это похоже на определение Физического Экстента (Physical Extent, PE) в терминологии LVM. (Logical Volume Manager (LVM) — системы управления логическими томами (Logical Volume, LV), используемая в операционной системе Linux. LVM предоставляет гораздо более широкую функциональность, чем система разделов (partitions) OC *DOS.
Том (Volume) - это структура данных ОС, содержащая указатели на множество физических блоков устройства хранения данных могущих быть не смежными. В LVM же, доступное пространство для хранения данных, представлено физическими томами (Physical Volume, PV), и это могут быть жёсткие диски, разделы или любые другие блочные устройства.
Метаданные ФС типа ext3/2 это – суперблок, таблица дескрипторов групп блоков (Дескриптор — здесь и далее, это структура с данными.), дескрипторы групп блоков и журнал.
Суперблок (Superblock) - содержит наиболее общую и важную информацию о файловой системе. В суперблоке наличествуют (не исключительно) следующие данные:
1. Размер блока файловой системы
2. Число (логических) блоков на группу блоков; о группах блоков пока лишь отметим, что для удобства адресации блоки (смежные физические или номера блоков ФС?), в ФС логически объединяются в группы. Тогда абсолютное смещение блока на разделе становится относительным от его смещения в группе блоков.
3. Число айнодов (inodes) на группу блоков; индексный узел (айнод) — еще одна структура данных, информация в которой имеет критическое значение для функционирования системы.
4. Сигнатура суперблока; содержит "магическое" число EF53h. Его волшебство заключается в том, что оно помогает идентифицировать суперблок, так как его резервная копия находится в каждой группе блоков.
5. Размер индексного дескриптора/узла (inode)
6. Общее число блоков и индексных дескрипторов (inodes) в файловой системе
Таблица дескрипторов групп блоков - в отделе, следующем сразу за суперблоком, содержится таблица дескрипторов групп блоков, представляющая собой массив указателей на структуры с данными, которые содержат (не исключительно) следующие поля описывающие группу блоков:
1. Указатель на битовую карту блоков - бинарный массив, записанный на устройстве хранения, содержащий битовую карту блоков этой группы. Битовая карта представляет собой последовательность нулей и единиц (1 — блок занят, 0 — блок свободен), причем каждый байт этой структуры записан справа налево (меньшие по порядковому номеру физические блоки содержатся по старшим адресам т. е. справа). Это часть дескриптора группы блоков — битовая карта блоков, необходима для хранения актуальной информации о занятых и свободных логических блоках, т. е. смежных физических блоков, представленных в ФС как блок файловой системы, например блок ФС может иметь общий размер 4096 байт, и при размере физического блока в 512 байт, всего в таком блоке ФС содержится 4096 / 512 = 8 физических блоков на устройстве. Так как ФС работает поверх разделов размер которых изначально ограничен, а размер блока ФС также фиксирован, общее количество блоков для раздела известно уже на на стадии формирования ФС.
2. Указатель на таблицу айнодов — в каждом дескрипторе групп блоков поддерживается своя таблица айнодов. Нумерация айнодов начинается с 1. Несколько номеров айнодов зарезервировано для специальных целей. Например, айнод номер 2 отведен для корневого каталога ("/").
5. Указатель на битовую карту айнодов. См. также битовая карта блоков
4. Число свободных блоков в группе блоков.
5. Число айнодов содержащих каталоги. Подробнее...
Айнод (i-node, inode) — i-node (айнодом или индексным дескриптором) называют структуру данных в традиционных файловых системах Unix, таких как UFS. Айнод хранит основную информацию о постоянных файлах, каталогах или других объектах файловой системы. У каждой такой структуры есть номер, и этот номер айнода заносится в таблицу айнодов в определенном месте устройства; по номеру же айнода ядро системы может считать содержимое айнода, включая указатели данных и прочее содержимое файла. Правильно не индексный дескриптор а файловый дескриптор. ФС семейства Ext не поддерживают (пока даже и ext4) динамическое выделение айнодов, т. е. их количество и следовательно количество файлов в ФС ограничено и если оно явно не указано, то оно вычисляется исходя из количества блоков в ФС и параметра байтов-на-айнод, утилиты создания ФС, которое также может быть переопределено. Динамическое создание айнодов это одна из пока планируемых но не реализованных возможностей в Ext4.
Точная причина использования «i» в узлах (нодах) неизвестна. В ответ на вопрос об этом один из пионеров Unix-систем Деннис Ритчи ответил:
Честно говоря, я мало об этом знаю. Это был всего лишь термин, который мы начали использовать. 'Индекс', как я полагаю, использовался из-за несколько необычной структуры файловой системы, хранившей информацию о доступе к файлам в плоском (двумерном) массиве на диске, а вся информация об иерархии каталогов хранилась отдельно. Таким образом, i-номер являлся индексом в этом массиве, i-node - выбранным элементом массива. (Приставка 'i-' использовалась в первой версии руководства; со временем дефис перестали употреблять).
Стандарты же POSIX, описывают поведение файловой системы в роли потомка традиционных файловых систем Unix. Так, айноды постоянных файлов должны иметь следующие атрибуты:
Длина файла в байтах.
ID устройства (это идентифицирует устройство, содержащее файл).
ID пользователя, являющегося владельцем файла.
ID группы файла.
Режим файла, определяющий какие пользователи могут считывать, записывать и запускать файл.
Timestamp указывает дату последнего изменения инода (ctime, change time), последней модификации содержимого файла (mtime, modification time), и последнего доступа (atime, access time).
Счетчик ссылок указывают количество жестких ссылок, указывающих на инод.
Указатели на блоки диска, хранящие содержимое файла. Подробнее...
пятница, 4 июня 2010 г.
Файловая система Ext4 для Linux: часть 1
Так как меня заинтриговал вопрос о том что же из себя представляют жёсткие диски, то я решил что постараюсь разобраться в этом вопросе и попутно, составить что-то вроде конспекта своих изысканий на эту тему. В основном пришлось читать статьи Википедии на русском и английском языках, и что-то из того что там расписано в подробностях я записал в этой заметке. Вообще же, это вводная часть для последующих заметок на тему использования файловой системы Ext4fs надеюсь будут сформированы, и поэтому то эта заметка называется «Файловая система Ext4 для Linux: часть 1» а не как то иначе. Если кому то это всё не безынтересно, и вы при этом слабо представляете о чём вообще речь, то вам будет полезно прочитать эту первую часть, так как например терминология довольно запутана и без чёткого понимания того что за всем этим лежит т. е. технических обобщённых подробностей, разобраться в вопросах связанных с дискам и ФС довольно проблематично.
Что такое жёсткий диск
Диск состоит из вращающихся круглых пластин выполненных из того или иного материала. На поверхности этих пластин нанесено ферромагнитное покрытие способное намагничиваться и таким образом нести на себе информацию.
нести на себе информацию.
Жесткие диски записывают данные путём намагничивания ферромагнитного материала для представления либо 0 или 1 двоичного состояния. Типичный дизайн HDD состоит из шпинделя, который содержит один или несколько плоских круглых дисков называемых «пластина», на которой данные и записываются. Пластины изготовлены из немагнитных материалов, как правило, из алюминиевого сплава или стекла, и покрыты тонким слоем магнитного материала, как правило, 10-20 нм толщины, - для справки толщина обычного листа бумаги 0.07-0.18 мм (70 000 - 180000 нм), - с наружным слоем углерода для защиты. Старые модели дисков, использовали оксид железа(III), как магнитный материал, но в настоящее время используются диски на основе сплавов кобальта.
Головки чтения-записи
Пластины вращаются на очень больших скоростях. Информация записывается на пластине, тогда как она вращается проходя под устройствами называемыми «головки чтения-записи», которые действуют в непосредственной близости (несколько десятков нанометров в новых устройствах) над магнитной поверхностью. Головка чтения-записи используется для обнаружения и изменения намагниченности материала непосредственно под ней. Естественно, что пластины имеют 2 стороны, и следовательно, 2 поверхности на которых данные могут быть записаны, обычно есть 2 головки на пластину - одна на каждой стороне, но это не всегда так. (Иногда термин «поверхность» подменяет «головку»).
Дорожки
Дорожки это узкие концентрические круговые полосы на магнитной поверхности расположенной на пластине, которые фактически на самом деле содержат области с записанными магнитными данными, записанными на диске. Они образуют круг и поэтому они двумерны. По крайней мере, одна головка необходима для чтения одной дорожки. Вся информация хранимая на жестком диске запи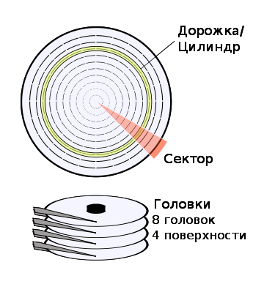 сывается на дорожки, а если более точно — в секторы на которые они поделены. Зачастую термины «дорожка» и «цилиндр» используются как эквивалентные.
сывается на дорожки, а если более точно — в секторы на которые они поделены. Зачастую термины «дорожка» и «цилиндр» используются как эквивалентные.
Цилиндры
Цилиндр образуется из каждой дорожки под определённым порядковым номером на пластине, но не на одной пластине, а на всех из имеющихся пластин, он охватывает все эти дорожки по всей поверхности каждой из имеющихся пластин способных хранить данные. Таким образом, это 3 .х мерный объект. Любая дорожка, состоящая в одном цилиндре может быть записана или прочитана, тогда как при этом актуатор с расположенными на нём головками чтения-записи, остается неподвижным во время операции чтения. Один из способов которым изготовителям дисков удалось увеличить скорость чтения с устройства, является увеличение количества пластин которые можно читать в данный момент времени. Таким образом цилиндр это логическая структура образованная пластинами и дорожками на них. Зачастую термины «цилиндр» и «дорожка» используются как эквивалентные.
Секторы
Дорожки подразделяются на несколько разделов. Каждый раздел называется сектором. В старых устройствах, сектора это наименьшие единицы хранения данных на жестком диске. Обычно сектор будет занимать 512 байт информации. Некоторые производители жестких дисков и программного обеспечения, разработчики пытаются изменить объем данных, хранимых в секторах до 4096 байт, т. е. довести физический размер сектора до значения в 4096 байт которое ныне обычно используется для указания размера блока при форматировании диска в файловую систему вроде ext4. Также, планируется что начиная с января 2011 года, производители устройств хранения, будут использовать 4096 байтный сектор, в качестве нового стандарта на размер сектора. [1] Следует различать понятия просто сектора (образованного геометрическим сектором) и сектора дорожки, так как эти два понятия могут заменять друг друга лишь при применении относительно к старым устройствам (MFM и RLL) у которых сектора с меньшими поверхностями, расположенные ближе к шпинделю, содержали такое же количество информации как и сек тора расположенные ближе к краям пластин, и были равнозначными в этом отношении. В отношении устройств (ATA/PATA) и более современных (SATA) это не так, в них каждый сектор дорожки, очерченный геометрическим сектором, расположенный ближе к краю пластины, может содержать большее количество записываемых секторов чем те что расположены ближе к шпинделю. Это значит что в отношении новых устройств речь уже идёт о количестве физических блоков на дорожку или сектор дорожки, нежели о количестве секторов на дорожку. (рис., А — дорожка, В — геометрический сектор, С — сектор дорожки, D — кластер).
тора расположенные ближе к краям пластин, и были равнозначными в этом отношении. В отношении устройств (ATA/PATA) и более современных (SATA) это не так, в них каждый сектор дорожки, очерченный геометрическим сектором, расположенный ближе к краю пластины, может содержать большее количество записываемых секторов чем те что расположены ближе к шпинделю. Это значит что в отношении новых устройств речь уже идёт о количестве физических блоков на дорожку или сектор дорожки, нежели о количестве секторов на дорожку. (рис., А — дорожка, В — геометрический сектор, С — сектор дорожки, D — кластер).
Блоки
Ранее в различных областях информатики, термин «блок» использовался для обозначения наименьшей порции хранимых данных, но термин «сектор», как представляется, стал более распространенным. Одна весьма вероятная причина для этого, это факт того что термин «блок» неоднократно применялся к кускам данным разных размеров и в отношении различных типов потоков данных, а не ограничивался наименьшим доступным объемом данных на устройствах хранения. Например, программа dd для Unix позволяет установить размер блока, который будут использоваться во время выполнения операций, с помощью параметра bs=байт. Но это не меняет фактический размер физического сектора носителя, только размер блоков, которыми dd будет манипулировать. А в мире UNIX/Linux, термин «блок» используют для обозначения сектора или группы секторов. Например, утилита fdisk для Linux обычно отображает таблицу разделов диска с использованием 512-байтных блоков, и при этом также используется термин «сектор», чтобы помочь описать размер диска фразой - 63 секторов на дорожку. То есть «блок» и «сектор» в технической литературе могут подменять друг друга. Но «блок» в отношении ФС, это может быть группа секторов, например 4096 байтный блок может состоять из 512 байтных секторов. Очевидно что термин сектор для определения наименьшей единицы хранения данных целесообразнее заменить на термин физический или дисковый блок наряду с использованием термина - логический блок для определения физических блоков связанных вместе с помощью внутренних отношений в файловой системе. То есть блок - это наименьшая величина хранимых данных по отношению к дискам и также по отношении к файловым системам в логику которых диски облечены.
Адресация Цилиндр-Головка-Сектор (CHS) и Логическая Адресация Блоков (LBA)
CHS (Cylinder-Head-Sector) это способ адресации к данным, который был реализован для старых дисковых устройствах хранения данных. Сейчас преимущественно не используется. Для доступа к сектору при CHS адресации использовались три значения в виде кортежа — (цилиндр/дорожка, поверхность/головка, сектор). Управлением получением доступа к данным осуществлялось на стороне операционной системы или непосредственно в прикладной программе. При CHS адресации наибольший возможный размер дискового устройства ограничен величиной около 8 400 000 000 байт (8.4 GB), так как 16-байтная запись в таблице разделов в MBR или EBR может содержать CHS-кортеж который ограничен только до значений (1023, 254, 63), что даёт всего 1024 возможных дорожек/цилиндров, 255 головок и 63 секторов на дорожку (значения для цилиндров и головок отсчитываются от 0, а значения секторов от 1), что в итоге и ограничивает вместительность устройства высчитываемой по формуле:
((1024 * 63) * 255) * 512 = 8 422 686 720 байт (около 8.4 GB)
Для примера более не используемые гибкие диски формата 3.5 дюйма (1.44 MB floppy disk) содержали 80 цилиндров (отсчёт от 0 до 79), 2 головки (отсчёт от 0 до 1) и 18 секторов (отсчёт от 1 до 18). И поэтому, их емкость в секторах вычисляется так: всего секторов = (80 * 18) * 2 = 2880, а ёмкость в байтах при при 512 байтном секторе: ((80 * 18) * 2) * 512 = 1 474 560 байт.
LBA (Logical block addressing) является простой линейной схемой адресации. Это адресация используемая в современных дисковых устройствах. Термин LBA может означать или адрес блока или сам блок на который этот адрес ссылается. При такой схеме адресации, адреса физических блоков располагаются в индексе начиная с первого блока LBA = 0, второго LBA = 1, и так далее. Схема LBA заменила собой ранние схемы адресации, которые возлагали детали адресации устройства хранения на программное обеспечение операционной системы. Основной среди них была схема CHS, однако же CHS не подходила устройствам отличным от жестких дисков (например ленты и сетевые системы хранения) и, как правило, не использовалась на них.
Протокол же SCSI, частично реализованный в ATA устройствах, представлял LBA как абстракцию. Первое формальное определение стандарта ATA интерфейса позволяло 28 битную адресацию блоков, используя для этого LBA или CHS. Стандарт АТА-1 при LBA адресации использовавшей 28 бит ограничивал ёмкость дисков до 128 Гибибайт, предполагая сектор размером 512 байт. В 2002 году стандарт ATA-6 представил LBA адресацию использовавшей 48 бит, расширяя возможный размер дисков до 128 Пебибайт, предполагая сектор размером 512 байт.
Потом был переход рынка от ATAPI к SATA устройствам, и последние полностью вытеснили с рынка своих предтечей, и действующая спецификация на них это SATA Revision 3.0 (SATA 6 Gb/s) от 27 мая 2009 года. В отличии от старых устройств, современные стали более интеллектуальны и совершеннее в используемых технологиях хранения данных и коррекции ошибок. Это достигается за счёт их внутренних электронно-программных компонентов, которые и обеспечивают работу устройства скрывая реализацию от ОС и программ. Обычно такие компоненты устройства это: контроллер работающий с системой во вне и включающий в себя: канал чтения/записи, контроллер диска и контрольный процессор RISC (микроконтроллер); схема Flash ROM содержащая программы устройства; схема контроля мотора шпинделя и актуатора; микросхема ROM в качестве кеш буфера.
Современные устройства сами производят коррекцию ошибок с помощью ECC, отслеживают разрушенные блоки производя переназначения их адресов на блоки из специального резерва (только при не успешной записи), также поддерживают технологию S.M.A.R.T которая позволяет отслеживать эти и другие параметры устройства отвечающие за его исправность.
P. S. О хронологических этапах дискостроения можно прочитать в статье, на английском языке, «Timeline: 50 Years of Hard Drives»
понедельник, 31 мая 2010 г.
OC Ubuntu 10.04 GNU/Linux: первое знакомство
Explore Ubuntu.
Like it?
Install it.
Love it!
*сие можно прочесть на обороте фиолетовой упаковки Ubuntu 10.04 LTS
Так как я уже упоминал в своей заметке в этом блоге о том что я собираюсь перейти на другую ОС, основанную так же как и моя предыдущая ОС на Linux и стеке программ и библиотек проекта GNU разработанного под эгидой фонда Free Software Foundation (FSF), то посему, я решил написать небольшую заметку о впечатлениях от процесса установки и использования этой самой новой ОС которая оказалась ни чем иным как Ubuntu 10.04 под кодовым именем Lucid Lynx, хотя тут как раз нужно заметить что в Ubuntu при работе с сетевыми хранилищами программного обеспечения которые называются репозитариями, используется только часть этого имени, и в моём случае это будет lucid без второй части lynx которая не используется и видимо присутствует для удобства и красоты.
Для меня знакомство с Linux началось давно, в 2004 году с дистрибутива Slackware 10.0 GNU/Linux, но несмотря на прошедшие 6 лет я могу сказать что по прежнему почти ничего не понимаю ни в Linux ни в программном обеспечении которое обычно используется в мире СПО и Linux. Поэтому, ничего выдающегося в области Знания Силы от меня ждать не приходится, но вместо этого есть лишь поверхностный взгляд пользователя. А поскольку я всегда использовал дистрибутивы-потомки от Slackware то можно считать что я свои впечатления от Debian+Ubuntu я буду сравнивать со Slackware+ , где плюс это дистрибутив-потомок с графической средой Xfce 4.6. Вот, Slackware vs. Ubuntu, здесь и далее речь будет вестись о них.
Получение дистрибутивов, может быть одинаковым в обоих случаях. Для этого нужно иметь скоростное интернет подключение и много интернет трафика что бы загрузить необходимые ISO9660 образы компакт или DVD дисков. Размеры могут соответственно различаться в пределах от 300 — 700 миллионов бит до 4.5 миллиардов бит для различных видов оптических носителей в расчёте на которые эти образы файловых систем и были собраны. А вот если вы хотите получить дистрибутив по почте в виде оптического диска то появляются существенные различия. Так что бы получить Slackware вам придётся заказать его в каком либо интернет магазине и оплатить заказ наложенным платежом при получение в почтовом отделении. Но вот Ubuntu, а до недавних времён так же даже и версию Kubuntu с оконной средой созданной в одноимённых проектах Qt/KDE вместо стандартного для Ubuntu GNOME, можно было заказать бесплатную мировую доставку одного компакт-диска с Ubuntu на нём - довольно существенное различие.
Установка так же существенно различается. Кстати можно отметить что установка Slackware от версии к версии остаётся очень стабильной в отношении использованных в инсталляторе технологий — это по прежнему старый добрый набор шелл скриптов который работает без запуска X.org графического сервера и соответственно может работать очень стабильно при условии что сами скрипты написаны и работают без ошибок. Лично я не встречал каких то особых проблем или сбоев в работе инсталляторов аля Slackware.
Другое дело Ubuntu который в свою очередь основан на Debian. Хотя я и видел раньше нечто на подобии Slackware'ского процесса установки в первых версиях Ubuntu, в те времена когда еще присылали по 2 диска вместо 1 как сейчас, в нынешние времена Ubuntu'вцы научились использовать один диск как для работы в режиме live-cd так и для установки системы что видимо и привело к тому что в нынешних версиях этого дистрибутива установка проходит в графическом режиме с запущенным X.org, а сама программа установки внешне и по своим повадкам стала очень походить на подобное же в процессе установки ОС Microsoft Windows XP, с той разницей что в случае Ubuntu 10.04 мне посчастливилось лицезреть чуть меньше рекламных и информационных текстов чем в случае проприетарного оппонента производства Microsoft. А вот несколько лет назад, одна из более ранних версий Ubuntu упорно зависала и не устанавливалась, что и остановило тогда меня от знакомства с этим дистрибутивом. Хотя и в этот раз программа установки не отработала без нареканий, так при попытке установить систему на пустые форматированные разделы программа установки пыталась удалить с них несуществующие файлы что приводило её к ошибке из-за из их отсутствия, хотя это и решилось после того как программа установки сама провела форматирование разделов тем самым убеждаясь что они свободны от файлов — как мило со стороны разработчиков этого ПО совершать такие оплошности, и кстати было неприятно то что мне не дали возможности самому решать с какими опциями форматировать диск — в отличии от Slackware где такая возможность есть. Хотя могу заметить что сама по себе программа установки стала гораздо лучше, так при выборе временной зоны появилась красивая интерактивная карта мира, а определение раскладки клавиатуры судя по всему разработчиками была доведена до совершенства — так ли это поживём увидим.
В этой версии Ubuntu 10.04 в качестве загрузчика ОС используется GRUB2, который мне не очень знаком, т.к. раньше в основном приходилось иметь дело с загрузчиком LILO, но всё не так уж и непонятно что бы останавливаться перед переходом на другой дистрибутив Linux. В этой части Ubuntu справилась на отлично и все мои ОС в количестве 1 типа Slackware уверено заняли свои места в списке ОС которые GRUB был по его мнению способен загрузить. Резюмируя нужно сказать что Ubuntu имеет хорошие шансы не установится на компьютеры с недостаточными ресурсами т.е. с объёмом оперативной памяти компьютера менее 256 миллионов бит о чём собственно и можно прочесть на внутренней стороне упаковки диска присылаемого компанией Canonical по почте. И всё это конечно ни в коей мере не применимо к Slackware. 16 миллионов бит оперативной памяти? Нет проблем — Slackware попытается справится и здесь хотя под такие скромные возможности скорее всего более уместно было подобрать что то более специализированное на поддержке старого и слабого компьютерного железа. Да и работа современных Linux серии 2.6 требуют по моим наблюдениям минимум 32 миллионов бит оперативной памяти да и то только для того что бы загрузить сам Linux и пару системных оболочек Bash.
Выбрав при загрузке в меню GRUB пункт 'Ubuntu, with Linux 2.6.32-21-generic' первое что я увидел и заметил это то что Plymouth использованный для создания красивого, положенного любой вменяемой современной ОС в мире, загрузочного экрана, а в Ubuntu 10.04 он как это и следовало ожидать тоже фиолетовый как и основная тема, и как упаковка — в общем в Ubuntu 10.04 — фиолетово всё до чего только смогли дотянутся разработчики этого дистрибутива, не успевает полностью скрыть от пользователей уставившихся в мониторы своих компьютеров исконную черноту Linux - свободной реализации замены Unix - мелькает, подло показывая свой неукрощённый оскал Си код ядра не желающий скрывать свои революционные порывы под покровом из декоративных ширм свойственных в этом мире почившим вождям революций. Что не может не радовать злопыхателей — они радостно указуют на этот недостаток тогда как все остальные ревнители глядят совсем в другую сторону AWN так же известного как Avant Window Navigator которого нет на диске в отличии от того же compiz'a, но который есть в репозитариях и который нужно загружать и устанавливать отдельно. Впрочем мне фиолетово и то и другое, вернее и те и другие, а AWN есть логичное продолжение compiz'a что не может не радовать ибо корпоративные пользователи могут видеть своими глазами что Linux это круто, совсем как Mac а Мак это круто разве не мак? Мак мак все знают что мак. А репутация крутой ОС это половина успеха.
Итак, в Ubuntu 10.04 в качестве оконной рабочей среды используется GNOME версии 2.30.0 а в последующих версиях дистрибутива ожидается использование GNOME версии 3.0 что конечно же сулит небывалые до сих пор улучшения взаимодействия пользователя с компьютером — дай то Бог. Пока же просто скажу что в этой версии GNOME, мне таки довелось наблюдать ошибку в его работе когда я пытался создать дополнительную панель на рабочем столе, новая панель не появлялась а поскольку я пытался сделать это несколько раз было довольно забавно когда сначала по верхней кромке рабочего стола образовалась невидимая но занимающая место панель — об её присутствии говорило то что панель которая там была изначально будучи отправленной в режим свободного перемещения не могла быть установлена на прежнее место — что-то, а именно невидимая панель занимала это место на рабочем столе не давая любым другим объектам располагаться там. Впрочем, после перезагрузки ноутбука невидимые панели которые были созданы раньше, штук 5 сразу, вдруг внезапно стали видимы и хотя они и располагались друг над другом всё таки пришлось потратить время на то что бы их все удалить. Хорошо хоть так всё обернулось, а вот если бы они остались прозрачными и постоянно присутствовали на рабочем столе не реагируя на нажатие кнопок «тачпада» или «мыши» то это было не очень забавно.
Из приятного, что касается системы в целом можно отметить довольно быструю загрузку и ещё более быструю процедуру выключения компьютера — как разработчики этого добились и чем при этом пришлось пожертвовать в пользу таких скоростей — для меня остаётся загадкой. Мой прежний «Slackware» дистрибутив выключался очень медленно даже по сравнению в предыдущими своими же версиями, и объяснялось это тем что во время выполнения скриптов выключения производилось обновления кэша разделяемых библиотек что нагружало и процессор и жёсткий диск и конечно занимало время, и довольно значительный его промежуток. Был конечно соблазн выключить это закомментировав соответствующие строки в скриптах, но потом я с этим смирился и оставил всё как было.
Из неприятного что связанно с этим дистрибутивом. Самое неприятное это отсутствие в ядре ОС поддержки виртуальной файловой системы usbfs предназначенной отображать подключённые к портам USB устройства, и соответственно необходимой для работы имеющихся у меня периферийных устройств, а именно модема Dlink DSL-200 gen III. Возможность поддержки usbfs в ядрах версии 2.6.32 всё же есть, но с недавних пор в ядрах поставляемых с Ubuntu эта подсистема отключена по причинам мне не известным. Также, была необходимость в подсистеме tun/tap предназначенной для создания виртуальных сетевых интерфейсов для приложений и эта подсистема доступна в Ubuntu но вопреки обычной традиции собирать эту подсистему в виде загружаемого модуля ядра, в системе Ubuntu он оказался уже загруженным при загрузке системы и его нет среди файлов модулей из чего можно сделать вывод что в Ubuntu решили сделать tun/tap присутствующим в ядре перманентно — причины и для этого решения остались за кадром. Впрочем это не критично сказывается на возможности для его использования если только приложение которое пытается его использовать не ограничено необходимостью во что бы то ни стало работать с этим только и исключительно в виде загружаемого модуля, впрочем — зачем бы?
Также из разнообразия программ, в Ubuntu 10.04 имеется в наличии compiz версии 0.8.4 который чудесно интегрирован с менеджером окон metacity и gtk-window-decorator …, и о ну надо же, ещё здесь есть ни много ни мало Mono JIT compiler version 2.4.4 собранный с сборщиком «мусора» Boehm (with typed GC) , но зато здесь нет программы patch которая мне оказалась необходимой для применения патча за номером 13 к Linux 2.6.32, впрочем она присутствует на установочном компакт-диске но не устанавливается во время первичной установки ОС. И в отличии от Slackware которые поставляются со всеми файлами необходимыми для компиляции программ, в Ubuntu всё что связано с компиляцией т.е. заголовочные файлы и т.п. находится в *-dev пакетах и сами эти пакеты на установочном диске отсутствуют, что например оказалось очень неудобно при пересборке ядра которое мне пришлось делать для включения поддержки выключенной в Ubuntu`вском ядре usbfs. Ни один из конфигураторов «ванильного» ядра которое я подобрал себе «на обочине» — GTK или ncurses не оказался для меня доступным так как обоим нужны были или libgtk-dev (название же, не очевидно, что бы его узнать пришлось долго просматривать списки доступных пакетов в менеджере пакетов Synaptic) или libncurses5-dev а их как не трудно догадаться как раз и не было. Обычная ситуация в итоге — нужно подключение к интернет что бы получить файлы которые нужны что бы получить работающее подключение к интернет. В итоге пришлось взять файл /boot/config-2.6.32-21-generic с настройками конфигурации Ubuntu`вского ядра, скопировать его в директорию с распакованными исходными текстами «ванильного» linux-2.6.32, затем наложить патч из файла patch-2.6.32.13.bz2, потом переименовать config-2.6.32-21-generic в .config и затем открыв этот файл в тектовом редакторе gedit найти там строчку или даже строчки:
#
# Miscellaneous USB options
#
# CONFIG_USB_DEVICEFS is not set
# CONFIG_USB_DEVICE_CLASS is not set
# CONFIG_USB_DYNAMIC_MINORS is not set
И здесь было нужно наугад, надеясь на везение, раскомментировать т. е. убрать «решётку» и заменить is not set на =y, что бы получить usbfs которая кстати в этом файле определяется параметром CONFIG_USB_DEVICEFS а вовсе не чем то вроде CONFIG_USBFS как наверное можно было ожидать. Но как бы там ни было, приведя этот параметр к виду CONFIG_USB_DEVICEFS=y и выполнив make oldconfig я тем памятным вечером (ночью) запустил компиляцию ядра, и забегая вперёд скажу что включение этой опции подключает поддержку usbfs. И, из-за того что всё что можно было пометить для сборки в виде модулей, разработчики Ubuntu таки и пометили, что лично для меня обратилось в сущий кошмар ожидания того момента когда же все эти треклятые не нужны мне совершенно бесконечные драйверы и файловые системы не прекратят компилироваться, и проще говоря это было долго, долго, долго, долго … больше чем 1,5 часа как обычно при настроенном в ручную ядре, отталкиваясь при этом от дистрибутивной конфигурации. Потом, после установки этого ядра, мне ещё долгое время, много раз, пришлось при загрузке GRUB править параметры нажимая на клавишу «е» для перехода к редактированию, стирать там Ubuntu`вское ядро и вписывать своё. Пфф... это было нудно. А всё потому что везде в инструкциях об этом написано что список загружаемых ОС и с их параметрами должен находится в файле menu.lst по адресу /boot/grub/menu.lst но а в действительности, сейчас этот файл носит имя grub.cfg что значит что не зная что искать вы этого не найдёте, и также в нём можно прочитать устрашающее предупреждение # DO NOT EDIT THIS FILE т. е. не редактируйте этот файл. Но, не смотря на столь грозное предупреждение, я всё же рискнул и добавил строчки для загрузки системы с моим ядром. Для этого я просто скопировал соответствующие строки из этого файла относящиеся к Ubuntu`вскому ядру и просто заменил имя файла ядра на нужное мне. После этого, при загрузке системы в меню ОС GRUB`а появилась строчка и с моими параметрами загрузки. Теперь всё плохо потому что я не верю в «ванильные» ядра больше. Вот так вот, хотели как лучше а получилось не Бог весть как. Патчи накладывать нельзя, ядро конфигурировать нельзя, программы компилировать нельзя — и в этом видимо выражается принцип Ubuntu «Just Work» (Просто работает).
Что еще мне не понравилось. Из более менее важного, учитывая мою ситуацию с жёстким диском, мне не понравилось отсутствие в дистрибутиве с компакт-диска пакета smartmontools с программами для мониторинга состояния жёсткого диска. И по моему это уже серьёзное упущение со стороны Canonical, ведь в любом компьютере есть жёсткий диск и следовательно есть постоянная необходимость иметь с самого начала работы системы и постоянно, инструмент для получения информации о состоянии его здоровья. Наверное в этом есть большая необходимость чем в установленном Mono. Например у меня нет ни одной программы для Mono и пока что он просто бесполезно занимает место на диске для которого же Canonical решила не поставлять необходимый системный софт. В чём здесь логика? Очень плохо Canonical, очень плохо!
И из-за привычки использовать htop в качестве менеджера процессов и most в качестве программы просмотра man страниц, мне не доставило особого удовольствия то что я обнаружил их отсутствие в базовой комплектации дистрибутива. Из-за какой такой традиции Debian в системе поставляет только less ? Это уже не постижимо — compiz и mono против smartctl и most. Мне уже хочется сказать пару ласковых коллективу Debian/Ubuntu по поводу их подхода к выбору приоритетов при формировании набора программ в этом дистрибутиве. И по моему они кое в чём не правы, когда они огульно убирают из дистрибутива все dev пакеты — хотя за этим и можно видеть рациональные мотивы — так как практика и здравый смысл показывают что нужно оставить некоторые, и когда убирают жизненно необходимые системные утилиты — неужели они таким образом экономят дисковое место на компакт-диске? Не самый удачный способ сэкономить!
Кроме прочего, мне не понравились два основных приложения из состава GNOME, а именно менеджер файлов Nautilus и эмулятор терминала gnome-terminal. Частично это вызвано объективными причинами а частично просто привычкой использовать примерно такие же программы которые выглядят и функционируют почти так же как и две вышеназванные. В отношении Nautilus к объективным причинам я прежде всего отношу его не способность при запуске из командной строки начинать работу в том каталоге в котором находится системная оболчка, т. е. если я открыв терминал в директории /tmp затем вызову экземпляр Nautilus то он откроет своё окно не в директории /tmp а в домашней папке пользователя, а что бы это обойти нужно явно указывать путь к рабочей директории что делать каждый раз очень неудобно. Также, «Основная панель инструментов» не кажется очень уместной или удобной в использовании, со своими кнопками «вперёд/назад» в стиле веб-браузера, их более удобная альтернатива это строка адреса оформленная в виде кнопок соответствующих папкам в дереве каталога в ветви которого вы в данный момент находитесь — в сочетании с вкладками и боковой панелькой с включённым отображением истории перемещений — вполне достаточно для удобной навигации по файловой структуре. Также боковая панель, и её режимы работы, сама по себе это вполне продуманный, удобный и функциональный элемент интерфейса. Это приводит к выводу что «Основная панель инструментов» это ненужный элемент, отнимающий вычислительные ресурсы и следовательно увеличивающий время загрузки и отклика. О функции «Фон и эмблемы...» и говорить не приходится, т. к. очевидна полна неуместность этого в менеджере файлов который должен быть прежде всего удобным - что значит функциональным, и удобным - что значит быстрым — как по времени загрузки так и по времени отклика; что означает что из таких программ нужно убрать всё лишнее, а «Фон и эмблемы...» это очевидно лишняя составляющая этой программы. И вот к Nautilus`у был добавлен Thunar как более простой и быстрый компаньон. Но его недостатки это отсутствие вкладок и функции запоминания истории посещённых директорий в левой боковой панели, хотя он и не страдает болезнью неможения открытия текущей директории, как Nautilus. И также можно провести объективные замеры времени загрузки Nautilus и Thunar с помощью утилиты time и ключа quit который оба испытуемых поддерживают.
| Thunar | Nautilus |
| real 0m0.040s | real 0m0.110s |
| user 0m0.020s | user 0m0.032s |
| sys 0m0.000s | sys 0m0.012s |
И из таблицы выше видно что Thunar почти в 3 раза быстрее чем Nautilus, хотя эти результаты неточны так как при множестве проверок результаты разнятся.
Что касается gnome-terminal то он был полностью заменён на xfce4-terminal так как последний по субъективным ощущениям он более быстр во время запуска чем gnome-terminal, и при этом оба приложения почти идентичны по функциям, настройкам и внешнему виду, не считая мигающего курсора у gnome-terminal.
Резюмируя, могу сказать что Debian/Ubuntu есть самый обычный дистрибутив на базе Linux. Linux по прежнему наполнен ошибками в коде и его по прежнему просто напросто опасно использовать на компьютере. Что-то конечно делается для устранения этого в рамках разработки дистрибутива, что-то делается в рамках разработки самого Linux и с помощью разнообразных патчей — для отслеживания и правильного применения которых собственно наверно и нужен отряд разработчиков Canonical — дай то Бог. Но, пока по всей видимости, Ubuntu есть что-то среднее между любым «домашним» дистрибутивом и полностью коммерческим таким как Red Hat. Это полу любительское полу индустриальное произведение, основной отличительный признак которого это бесплатная рассылка дисков по миру, тогда как по уровню проблем, недоработок и опасности использования на дорогом оборудовании этот дистрибутив не очень сильно выигрывает на фоне всех остальных.
Подписаться на:
Комментарии (Atom)